Welcome
Welcome to PearWiseAI, your AI as a Service for evaluating LLM Applications. With PearWiseAI, developers can evaluate the underlying Large Language Model System (LLMS) in their LLM Apps, quickly, affordably, and at scale.
What is a Large Language Model System?
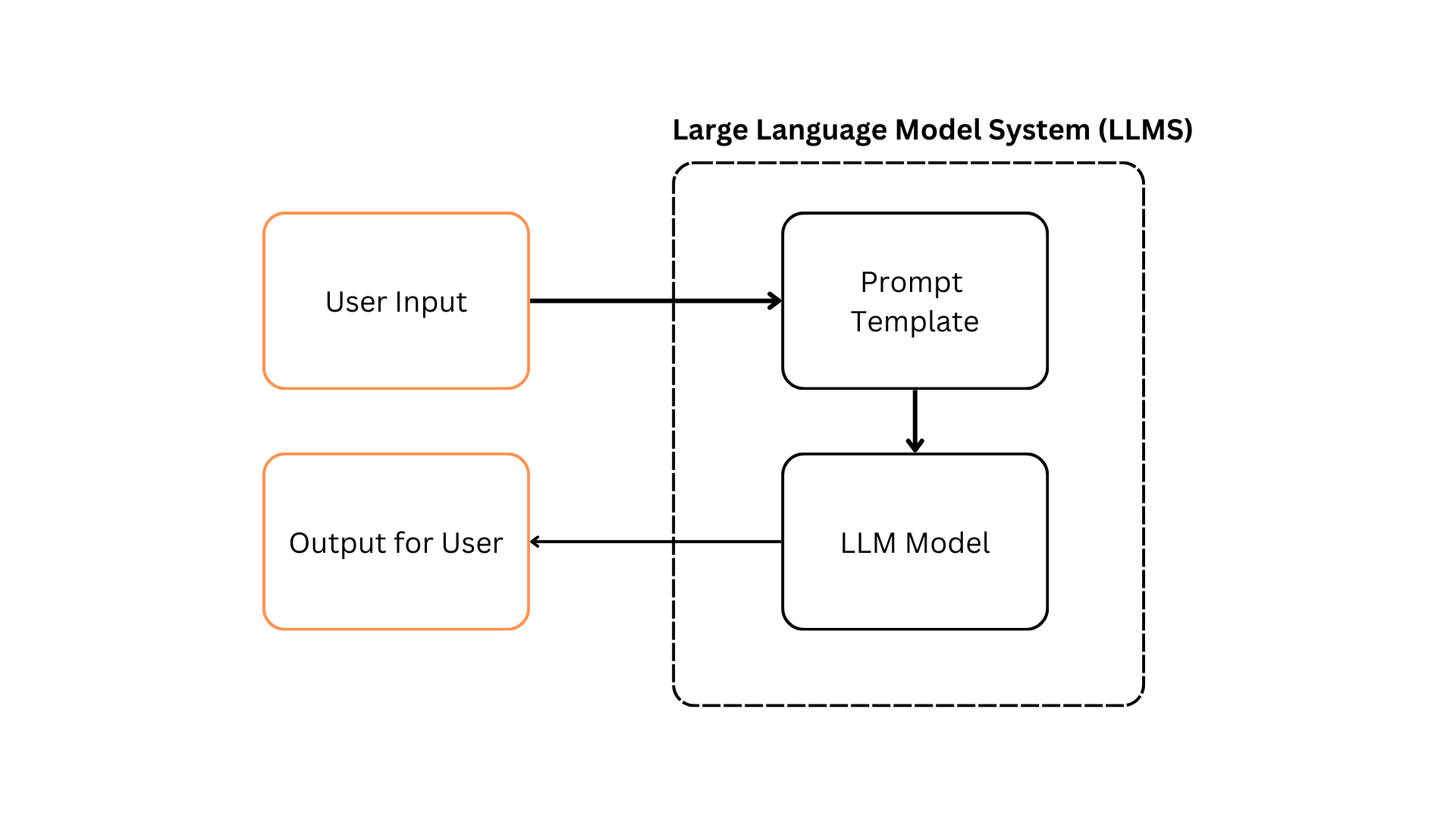
We define Large Language Model System (LLMS) as the combination of a Large Language Model (LLM) with your addition of Prompt Tempalates or any additional code layer or logic you want to add on top of the foundational LLM.
PearWiseAI is LLMS agnostic, meaning we treat your LLMS as a blackbox. Developers are free to use whatever LLM or frameworks they are comfortable with. We are only concerned with its inputs and outputs.
Throughout the documentation, we will be loosely using the word LLM App and LLMS interchangably.
Why is it important to evaluate LLMS?
Evaluating LLMS, like those used for a TutorGPT, is crucial for various reasons:
Performance Benchmarks and Regression Testing
As LLMS evolve, they are frequently updated with new features, bug fixes, or data. Regular updates can impact a system's performance. Being able to benchmark an LLMS's performance allows for regression testing helps ensure that the performance remains consistent, or ideally improves, after each update.
Facilitating Continuous Integration and Continuous Deployment (CI/CD)
In modern software development practices, where updates are frequent, regression testing is essential for CI/CD pipelines, allowing for rapid and safe deployment of changes.
Bias and Fairness
LLMS can inadvertently learn and perpetuate biases present. This could present itself as the LLMS being unable to teach certain topics well, or unable to handle certain edge use cases. A diverse test suite helps us ensure that all areas of possible use cases are well tested before deployment.
Why is Evaluating LLMS so difficult?
LLMS are difficult to evaluate due to the subjective nature of their outputs.
Many existing LLMOps tools run the new model against a suite of inputs and allow developers to make judgement on which is better. It requires human intervention to come in and score the goodness of the output.
This form of manual developer evaluation presents massive challenges:
- High Cost: Domain experts and Developer time is costly. Having them make these manual scoring for every output costs a lot.
- Time Intensive: Evaluating these outputs manually is labor intensive and slow, hindering development cycles. Human evaluation cannot be automated for a CI/CD pipeline.
- Unreliable: When these scoring are done fully by human, the scores fluctuate between different domain experts.
PearWiseAI's Solution
To tackle these challenges, we believe that evaluation should be done by AI models trained on domain experts and user evaluations.
To achieve this we provide the following:
- Scoring Framework: A systematic scoring framework and tools for evaluating LLMS outputs.
- Convenient SDKs and APIs: Software Development Kits (SDKs) and Application Programming Interfaces (APIs) for scoring of user and domain experts' feedback.
- Customtrained Evaluator AI: Based on the input/outputs and scores collected, we continuously auto-train an evaluator AI to score outputs instead.
Instead of having domain experts evaluate these outputs directly, PearWiseAI collects their scoring to form a dataset to train an EvaluatorAI. This EvaluatorAI is then able to perform scoring on their behalf faster, cheaper, and at scale.
Responsibilities
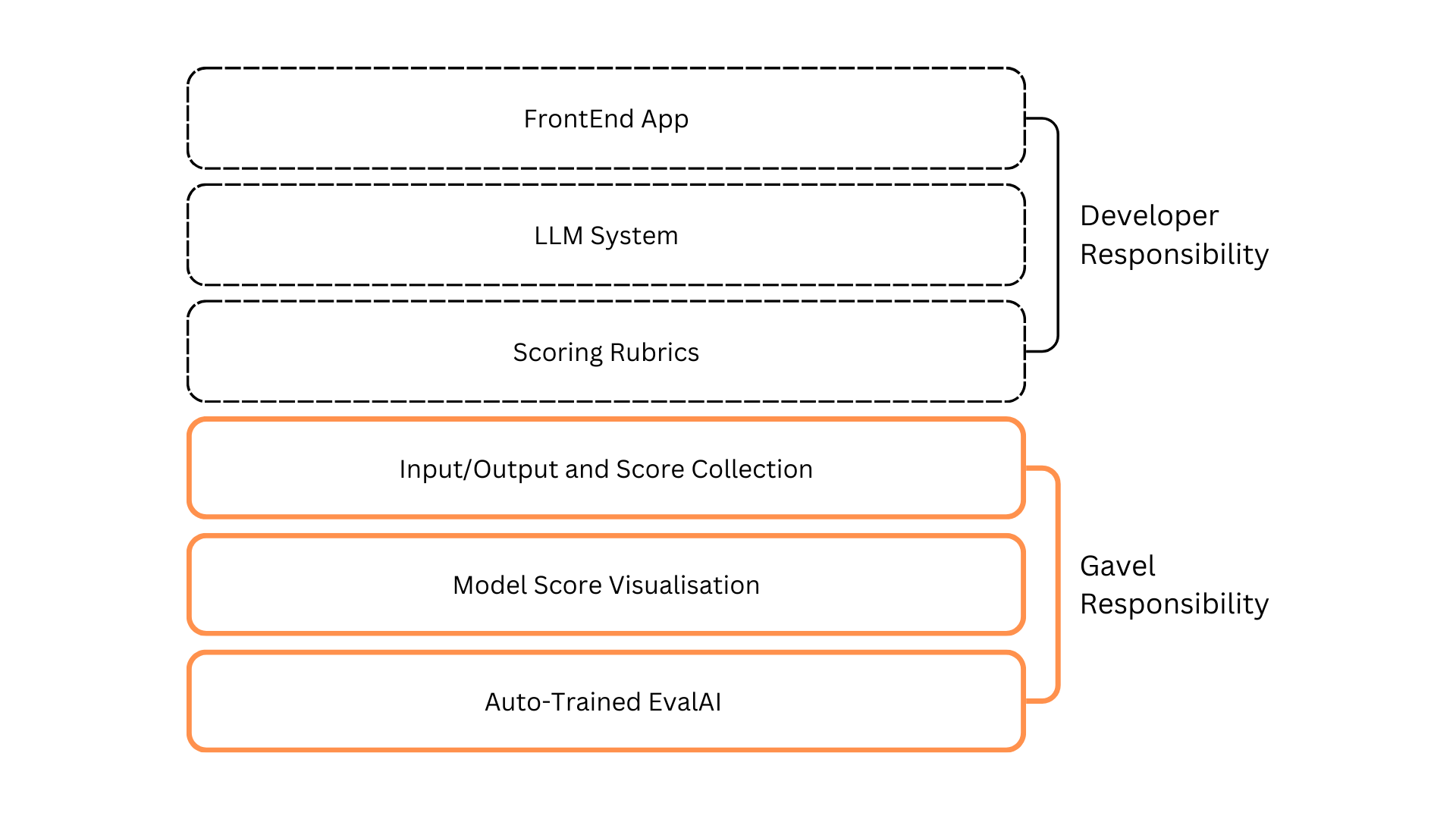
The diagram above describes the split of responsibilities between PearWiseAI and Developer. PearWiseAI is focused on providing the APIs and SDKs needed to make user and domain expert feedback collection easy, as well as to provide AI as a service to evaluate your model.